編輯:關於Android編程
android中網絡請求回來數據之後,我們要對其解析。請求的返回的結果格式如果不是自定義協議;那麼返回的數據通常是xml,json,html形式的數據了。
下面就是針對上面3種格式進行解析。
xml解析使用工具:在android中推薦使用pull解析,還有其他的dom,sax解析。
json解析使用工具:推薦使用Fastjson,由阿裡提供。還有其他的如JackSon,Gson解析。
html解析使用工具:推薦使用Jsoup,還有其他的如HtmlParser;關於使用這個,網絡上的爬蟲就是這樣子的。
//android推薦的解析方式
public class PULL {
public static List pullXML() throws Exception {
// 獲取person文件的輸入流
InputStream is = PULL.class.getClassLoader().getResourceAsStream(
"person.xml");
// 用來存放解析的person對象
List persons = null;
// 一個標記
boolean flag = false;
Person person = null;
// 實例化一個XmlPullParser對象
XmlPullParser parser = Xml.newPullParser();
// 設置輸入流的編碼
parser.setInput(is, "UTF-8");
// 設置第一個事件,從這個事件開始解析文檔
int eventCode = parser.getEventType();
// 設定結束標記,如果是END_DOCUEMNT,解析就結束了
while (eventCode != XmlPullParser.END_DOCUMENT) {
switch (eventCode) {
case XmlPullParser.START_DOCUMENT:
// 開始解析的時候我們一般做一些初始化的操作
persons = new ArrayList();
break;
case XmlPullParser.START_TAG:
// 判斷當前的元素是否是需要檢索的元素
if ("person".equals(parser.getName())) {
flag = true;
person = new Person();
//"person"節點的第一個屬性值
person.setId(Integer.valueOf(parser.getAttributeValue(0)));
}
if (flag) { // 為檢索的元素賦值
if ("name".equals(parser.getName())) {
//"name"節點後的值
person.setName(parser.nextText());
} else if ("age".equals(parser.getName())) {
person.setAge(Integer.valueOf(parser.nextText()));
}
}
break;
case XmlPullParser.END_TAG: // 結束標簽,判斷一個對象是否結束,結束後添加到集合中
if ("person".equals(parser.getName()) && person != null) {
flag = false;
persons.add(person);
person = null;
}
break;
}
// 這一步很重要,該方法返回一個事件碼,也是觸發下一個事件的方法
eventCode = parser.next(); // 取下個標簽
}
return persons;
}
}
public class DOM {
public static List domXML() throws Throwable {
// 獲得xml文件的輸入流
InputStream is = MainActivity.class.getClassLoader()
.getResourceAsStream("person.xml");
List persons = new ArrayList();
// 定義一個工廠API,程序可以從這個API裡得到一個能夠從XML文檔中產生DOM對象的解析器- 翻譯的不好
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(is);
// 返回文檔的根元素
Element rootElement = (Element) document.getDocumentElement();
// 獲取一個Node集合
NodeList nodes = rootElement.getElementsByTagName("person");
// 遍歷Node集合
for (int i = 0; i < nodes.getLength(); i++) {
Element personElement = (Element) nodes.item(i);
Person person = new Person();
person.setId(Integer.valueOf(personElement.getAttribute("id")));
NodeList childNodes = personElement.getChildNodes();
for (int j = 0; j < childNodes.getLength(); j++) {
Node childNode = childNodes.item(j);
// 判斷子Note的類型為元素Note
if (childNode.getNodeType() == Node.ELEMENT_NODE) {
Element childElement = (Element) childNode;
if ("name".equals(childElement.getNodeName())) {
person.setName(childElement.getFirstChild()
.getNodeValue());
} else if ("age".equals(childElement.getNodeName())) {
person.setAge(Integer.valueOf(childElement
.getFirstChild().getNodeValue()));
}
}
}
persons.add(person);
}
return persons;
}
}
public class SAX extends DefaultHandler {
public static List sax_XML() throws Exception {
InputStream inputStream = MainActivity.class.getClassLoader()
.getResourceAsStream("person.xml");
if (inputStream != null) {
Log.d("inputStream", inputStream + "");
} else {
Log.e("inputStream", inputStream + "為空");
}
SAX saXforHandler = new SAX();
SAXParserFactory spf = SAXParserFactory.newInstance();
SAXParser saxParser = spf.newSAXParser();
saxParser.parse(inputStream, saXforHandler);
List list = saXforHandler.getPersons();
inputStream.close();
return list;
}
/**
* This is log.d TAG
*/
private static final String TAG = "SAXTag";
/**
* Store persons 存儲人數組
*/
private List persons;
/**
* a Person
*/
private Person person;
/**
* recode the name of current tag
*/
private String tag;
/**
* When startDocument,you can initial something in this method
* 當文檔開始時,會調用這個方法
*/
@Override
public void startDocument() throws SAXException {
persons = new ArrayList();
Log.d(TAG, "the sax is starting");
}
/**
* invoke the method after endDocument 文檔結束時會調用這個方法
*/
@Override
public void endDocument() throws SAXException {
Log.d(TAG, "endDocument");
}
/**
* invoke when startElement 開始讀取元素時候調用這個方法
*/
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
if ("person".equals(localName)) {
for (int i = 0; i < attributes.getLength(); i++) {
Log.d(TAG, "attributes.getLength" + attributes.getLength());
Log.d(TAG, "attributesName: " + attributes.getLocalName(i)
+ "_attributesValue" + attributes.getValue(i));
person = new Person();
person.setId(Integer.valueOf(attributes.getValue(i)));
}
}
tag = localName;
Log.i(TAG, "localName = " + localName);
}
/**
* read the element content 讀取元素裡面的內容。 比如說讀到age,age的內容是21.這個方法就是來讀21的
*/
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
String data = new String(ch, start, length).trim();
if (!"".equals(data)) {
Log.i(TAG, "Content: " + data);
}
if ("name".equals(tag)) {
person.setName(data);
} else if ("age".equals(tag)) {
person.setAge(Integer.valueOf(data));
}
}
/**
* 一個元素結束時候調用 就是遇到反斜槓時候調用
*/
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
if ("person".equals(localName) && person != null) {
persons.add(person);
person = null;
}
tag = null;
}
private List getPersons() {
return persons;
}
}
/**
*
*
* JSON.toJSONString;用於將實體類對象或實體集合轉為Json格式字符
* JSON.parseObject,JSON.parseArray用於將json格式字符轉為實體對象或實體集合
*
* 類似的實體與JSON格式之間的轉換工具還有Gson,JackSon;
*
* @author ZhangSheng
*
*/
public class FastJson {
private static String TAG = "FastJson";
/**
* 將實體對象或集合轉為jsonsString
*
* @param object
* @return
*/
public static String toJsonString(Object object) {
return JSON.toJSONString(object);
}
/**
* 將jsonString轉為實體對象
*
* @param text
* @param clazz
* @return
*/
public static T parseObject(String text, Class clazz) {
T object = JSON.parseObject(text, clazz);
return object;
}
/**
* 將jsonString轉為實體集合
*
* @param text
* @param clazz
* @return
*/
public static List parseArray(String text, Class clazz) {
List array = JSON.parseArray(text, clazz);
return array;
}
/****************************** 測試 ***************************************/
public static void test() {
StudentInfo studentInfo1 = new StudentInfo("11", "11", 11);
StudentInfo studentInfo2 = new StudentInfo("11", "11", 11);
List students = new ArrayList<>();
students.add(studentInfo1);
students.add(studentInfo2);
ClassInfo classInfo = new ClassInfo("1", "1", students);
String students_Str = FastJson.toJsonString(students);
Log.d(TAG, "students_Str=" + students_Str + "\n\n");
String studentInfo_Str = FastJson.toJsonString(studentInfo1);
String classInfo_Str = FastJson.toJsonString(classInfo);
Log.d(TAG, "studentInfo_Str=" + studentInfo_Str + "\n classInfo_Str="
+ classInfo_Str);
StudentInfo parseObject = FastJson.parseObject(studentInfo_Str,
StudentInfo.class);
Log.d(TAG, "studentInfo=" + parseObject + "\n\n");
List parseArray = FastJson.parseArray(students_Str, StudentInfo.class);
Log.d(TAG, "StudentInfos=" + parseArray + "\n\n");
}
public static class StudentInfo {
public String id;
public String name;
public int age;
public StudentInfo() {
super();
}
public StudentInfo(String id, String name, int age) {
super();
this.id = id;
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "StudentInfo [id=" + id + ", name=" + name + ", age=" + age
+ "]";
}
}
public static class ClassInfo {
public String id;
public String name;
public List students;
public ClassInfo(String id, String name, List students) {
super();
this.id = id;
this.name = name;
this.students = students;
}
public ClassInfo() {
super();
}
@Override
public String toString() {
return "ClassInfo [id=" + id + ", name=" + name + ", students="
+ students + "]";
}
}
}
Jsoup相關內容:涉及到html數據的輸入,從html中抽取數據,修改html中的數據這三個部分。
1.解析一個Html字符串: 使用靜態Jsoup.parse(String html) 方法或 Jsoup.parse(String html, String baseUri) 如: String html = "
Parsed HTML into a doc.
"; Document doc = Jsoup.parse(html); 另一個方法提供的參數 baseUri 是用來將相對 URL 轉成絕對URL; 一旦擁有了一個Document,你就可以使用Document中適當的方法或它父類 Element和Node中的方法來取得相關數據 2.解析一個body片段: 假如你有一個HTML片斷 (比如. 一個 div 包含一對 p 標簽; 一個不完整的HTML文檔) 想對它進行解析。 使用Jsoup.parseBodyFragment(String html) String html = "Lorem ipsum.
"; Document doc = Jsoup.parseBodyFragment(html); Element body = doc.body(); 使用Document.body()方法能夠取得文檔body元素的所有子元素,與 doc.getElementsByTag("body")相同。 3.從一個網站Url上加載一個Document: 使用Jsoup.connect(String url) 如: Document doc = Jsoup.connect("http://example.com/").get(); String title = doc.title(); 或者使用 該方法,只支持http和https協議; Document doc = Jsoup.connect("http://example.com") .data("query", "Java") .userAgent("Mozilla") .cookie("auth", "token") .timeout(3000) .post(); 4.加載本地硬盤上的html文件: 使用Jsoup.parse(File in, String charsetName, String baseUri) baseUri 參數用於解決文件中URLs是相對路徑的問題。如果不需要可以傳入一個空的字符串。 另外還有一個方法Jsoup.parse(File in, String charsetName) 它使用文件的路徑做為 baseUri, 這個方法適用於如果被解析文件位於網站的本地文件系統,且相關鏈接也指向該文件系統。 如: File input = new File("/tmp/input.html"); Document doc = Jsoup.parse(input, "UTF-8", "http://example.com/");
1.使用dom方法來遍歷一個document:
經過上面的數據的輸入之後,我們可以獲取到一個document對象。之後我們將對這個對象做數據抽取;
基本代碼如下:這是是一個本地html文件抽取:
File input = new File("/tmp/input.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://example.com/");
Element content = doc.getElementById("content");
Elements links = content.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
}
下面是一些常見的方法:
查找元素
getElementById(String id)
getElementsByTag(String tag)
getElementsByClass(String className)
getElementsByAttribute(String key) (and related methods)
Element siblings: siblingElements(), firstElementSibling(), lastElementSibling(); nextElementSibling(), previousElementSibling()
Graph: parent(), children(), child(int index)
元素數據
attr(String key)獲取屬性attr(String key, String value)設置屬性
attributes()獲取所有屬性
id(), className() and classNames()
text()獲取文本內容text(String value) 設置文本內容
html()獲取元素內HTMLhtml(String value)設置元素內的HTML內容
outerHtml()獲取元素外HTML內容
data()獲取數據內容(例如:script和style標簽)
tag() and tagName()
操作HTML和文本
append(String html), prepend(String html)
appendText(String text), prependText(String text)
appendElement(String tagName), prependElement(String tagName)
html(String value)
2.使用選擇器語法來查找元素:
使用Element.select(String selector) 和 Elements.select(String selector)
如:
File input = new File("/tmp/input.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://example.com/");
Elements links = doc.select("a[href]"); //帶有href屬性的a元素
Elements pngs = doc.select("img[src$=.png]");
//擴展名為.png的圖片
Element masthead = doc.select("div.masthead").first();
//class等於masthead的div標簽
Elements resultLinks = doc.select("h3.r > a"); //在h3元素之後的a元素
說明
jsoup elements對象支持類似於CSS (或jquery)的選擇器語法,來實現非常強大和靈活的查找功能。.
這個select 方法在Document, Element,或Elements對象中都可以使用。且是上下文相關的,因此可實現指定元素的過濾,或者鏈式選擇訪問。
Select方法將返回一個Elements集合,並提供一組方法來抽取和處理結果。
Selector選擇器概述
tagname: 通過標簽查找元素,比如:a
ns|tag: 通過標簽在命名空間查找元素,比如:可以用 fb|name 語法來查找 元素
#id: 通過ID查找元素,比如:#logo
.class: 通過class名稱查找元素,比如:.masthead
[attribute]: 利用屬性查找元素,比如:[href]
[^attr]: 利用屬性名前綴來查找元素,比如:可以用[^data-] 來查找帶有HTML5 Dataset屬性的元素
[attr=value]: 利用屬性值來查找元素,比如:[width=500]
[attr^=value], [attr$=value], [attr*=value]: 利用匹配屬性值開頭、結尾或包含屬性值來查找元素,比如:[href*=/path/]
[attr~=regex]: 利用屬性值匹配正則表達式來查找元素,比如: img[src~=(?i)\.(png|jpe?g)]
*: 這個符號將匹配所有元素
Selector選擇器組合使用
el#id: 元素+ID,比如: div#logo
el.class: 元素+class,比如: div.masthead
el[attr]: 元素+class,比如: a[href]
任意組合,比如:a[href].highlight
ancestor child: 查找某個元素下子元素,比如:可以用.body p 查找在"body"元素下的所有 p元素
parent > child: 查找某個父元素下的直接子元素,比如:可以用div.content > p 查找 p 元素,也可以用body > * 查找body標簽下所有直接子元素
siblingA + siblingB: 查找在A元素之前第一個同級元素B,比如:div.head + div
siblingA ~ siblingX: 查找A元素之前的同級X元素,比如:h1 ~ p
el, el, el:多個選擇器組合,查找匹配任一選擇器的唯一元素,例如:div.masthead, div.logo
偽選擇器selectors
:lt(n): 查找哪些元素的同級索引值(它的位置在DOM樹中是相對於它的父節點)小於n,比如:td:lt(3) 表示小於三列的元素
:gt(n):查找哪些元素的同級索引值大於n,比如: div p:gt(2)表示哪些div中有包含2個以上的p元素
:eq(n): 查找哪些元素的同級索引值與n相等,比如:form input:eq(1)表示包含一個input標簽的Form元素
:has(seletor): 查找匹配選擇器包含元素的元素,比如:div:has(p)表示哪些div包含了p元素
:not(selector): 查找與選擇器不匹配的元素,比如: div:not(.logo) 表示不包含 class=logo 元素的所有 div 列表
:contains(text): 查找包含給定文本的元素,搜索不區分大不寫,比如: p:contains(jsoup)
:containsOwn(text): 查找直接包含給定文本的元素
:matches(regex): 查找哪些元素的文本匹配指定的正則表達式,比如:div:matches((?i)login)
:matchesOwn(regex): 查找自身包含文本匹配指定正則表達式的元素
注意:上述偽選擇器索引是從0開始的,也就是說第一個元素索引值為0,第二個元素index為1等
可以查看Selector API參考來了解更詳細的內容
3.抽取元素屬性,文本,html
要取得一個屬性的值,可以使用Node.attr(String key) 方法
對於一個元素中的文本,可以使用Element.text()方法
對於要取得元素或屬性中的HTML內容,可以使用Element.html(), 或 Node.outerHtml()方法
如:
String html = "An example link.
";
Document doc = Jsoup.parse(html);//解析HTML字符串返回一個Document實現
Element link = doc.select("a").first();//查找第一個a元素
String text = doc.body().text(); // "An example link"//取得字符串中的文本
linkHref = link.attr("href"); // "http://example.com/"//取得鏈接地址
String linkText = link.text(); // "example""//取得鏈接地址中的文本
String linkOuterH = link.outerHtml();
// "example"
String linkInnerH = link.html(); // "example"//取得鏈接內的html內容
說明
上述方法是元素數據訪問的核心辦法。此外還其它一些方法可以使用:
Element.id()
Element.tagName()
Element.className() and Element.hasClass(String className)
這些訪問器方法都有相應的setter方法來更改數據.
4.處理URLs:
在你解析文檔時確保有指定base URI,然後使用 abs: 屬性前綴來取得包含base URI的絕對路徑
如:
Document doc = Jsoup.connect("http://www.open-open.com").get();
Element link = doc.select("a").first();
String relHref = link.attr("href"); // == "/"
String absHref = link.attr("abs:href"); // "http://www.open-open.com/"Html數據的修改:
1.設置屬性的值:
使用 Element.attr(String key, String value), 和 Elements.attr(String key, String value).
Element.addClass(String className) 和 Element.removeClass(String className) 方法。
如:
doc.select("div.masthead").attr("title", "jsoup").addClass("round-box");
2.設置一個元素的Html內容:
Element.html(String html) 這個方法將先清除元素中的HTML內容,然後用傳入的HTML代替。
Element.prepend(String first) 和 Element.append(String last) 方法用於在分別在元素內部HTML的前面和後面添加HTML內容
Element.wrap(String around) 對元素包裹一個外部HTML內容。
如:
Element div = doc.select("div").first(); //
div.html("
lorem ipsum
"); //lorem ipsum
div.prepend("First
");//在div前添加html內容 div.append("Last
");//在div之後添加html內容 // 添完後的結果:First
lorem ipsum
Last
Element span = doc.select("span").first(); // One span.wrap("
/**
* Example program to list links from a URL.
*/
public class ListLinks {
public static void main(String[] args) throws IOException {
Validate.isTrue(args.length == 1, "usage: supply url to fetch");
String url = args[0];
print("Fetching %s...", url);
Document doc = Jsoup.connect(url).get();
Elements links = doc.select("a[href]");
Elements media = doc.select("[src]");
Elements imports = doc.select("link[href]");
print("\nMedia: (%d)", media.size());
for (Element src : media) {
if (src.tagName().equals("img"))
print(" * %s: <%s> %sx%s (%s)",
src.tagName(), src.attr("abs:src"), src.attr("width"), src.attr("height"),
trim(src.attr("alt"), 20));
else
print(" * %s: <%s>", src.tagName(), src.attr("abs:src"));
}
print("\nImports: (%d)", imports.size());
for (Element link : imports) {
print(" * %s <%s> (%s)", link.tagName(),link.attr("abs:href"), link.attr("rel"));
}
print("\nLinks: (%d)", links.size());
for (Element link : links) {
print(" * a: <%s> (%s)", link.attr("abs:href"), trim(link.text(), 35));
}
}
private static void print(String msg, Object... args) {
System.out.println(String.format(msg, args));
}
private static String trim(String s, int width) {
if (s.length() > width)
return s.substring(0, width-1) + ".";
else
return s;
}
}
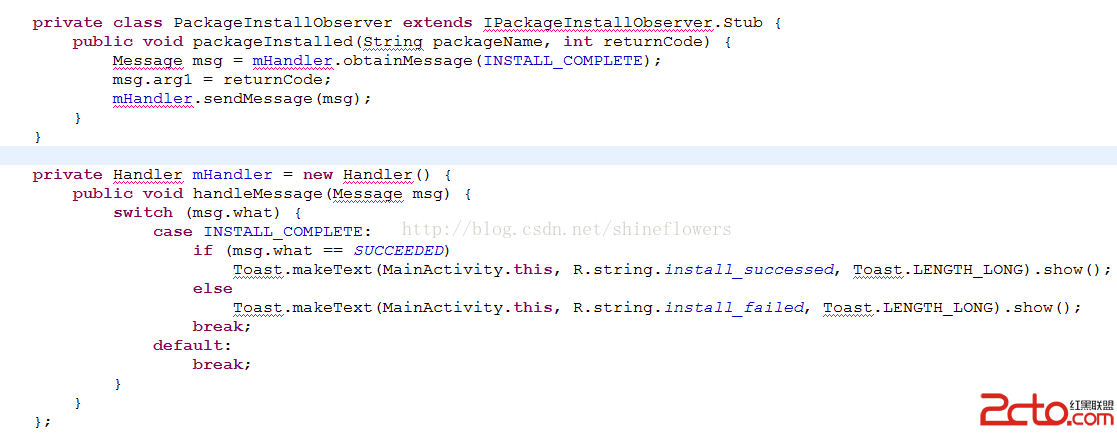 Android實現靜默安裝
Android實現靜默安裝
一般情況下,Android系統安裝apk會出現一個安裝界面,用戶可以點擊確定或者取消來進行apk的安裝。 但在實際的項目需求中,有一種需求,就是希望apk在後台安裝(不出
 Android 得到控件在屏幕中的坐標
Android 得到控件在屏幕中的坐標
package xiaosi.location; import android.app.Activity; import android.os.Bund
 徹底明白Android中AIDL及其使用
徹底明白Android中AIDL及其使用
1、為什麼要有AIDL? 無論學什麼東西,最先得弄明白為什麼要有這個東西,不要說存在即是合理,存在肯定合理,但是你還是沒有明白。對於AIDL有一些人的淺顯概念就是,AID
 微信理財通收益計算 微信理財通收益如何
微信理財通收益計算 微信理財通收益如何
你現在還是把錢都存在余額寶?相信你也注意到,現在理財方式越來越多,余額寶的收益也越來越低,如今微信也有理財通,也很多朋友加入購買。對微信理財通手機以了解?下