編輯:關於Android編程
可以直接復制實驗,
解析doc,要tm-extractors-0.4.jar這個包
解析xls,要jxl.jar這個包
import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.net.MalformedURLException; import java.net.URL; import java.net.URLConnection; import java.util.ArrayList; import java.util.List; import java.util.zip.ZipEntry; import java.util.zip.ZipException; import java.util.zip.ZipFile; import jxl.Cell; import jxl.CellType; import jxl.DateCell; import jxl.NumberCell; import jxl.Sheet; import jxl.Workbook; import org.apache.http.util.EncodingUtils; import org.textmining.text.extraction.WordExtractor; import org.xmlpull.v1.XmlPullParser; import org.xmlpull.v1.XmlPullParserException; import android.os.Environment; import android.util.Xml;
public static String readDOC(String path) {
// 創建輸入流讀取doc文件
FileInputStream in;
String text = null;
// Environment.getExternalStorageDirectory().getAbsolutePath()+ "/aa.doc")
try {
in = new FileInputStream(new File(path));
int a= in.available();
WordExtractor extractor = null;
// 創建WordExtractor
extractor = new WordExtractor();
// 對doc文件進行提取
text = extractor.extractText(in);
System.out.println("解析得到的東西"+text);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
if (text == null) {
text = "解析文件出現問題";
}
return text;
}
public static String readXLS(String path) {
String str = "";
try {
Workbook workbook = null;
workbook = Workbook.getWorkbook(new File(path));
Sheet sheet = workbook.getSheet(0);
Cell cell = null;
int columnCount = sheet.getColumns();
int rowCount = sheet.getRows();
for (int i = 0; i < rowCount; i++) {
for (int j = 0; j < columnCount; j++) {
cell = sheet.getCell(j, i);
String temp2 = "";
if (cell.getType() == CellType.NUMBER) {
temp2 = ((NumberCell) cell).getValue() + "";
} else if (cell.getType() == CellType.DATE) {
temp2 = "" + ((DateCell) cell).getDate();
} else {
temp2 = "" + cell.getContents();
}
str = str + " " + temp2;
}
str += "\n";
}
workbook.close();
} catch (Exception e) {
}
if (str == null) {
str = "解析文件出現問題";
}
return str;
}
public static String readDOCX(String path) {
String river = "";
try {
ZipFile xlsxFile = new ZipFile(new File(path));
ZipEntry sharedStringXML = xlsxFile.getEntry("word/document.xml");
InputStream inputStream = xlsxFile.getInputStream(sharedStringXML);
XmlPullParser xmlParser = Xml.newPullParser();
xmlParser.setInput(inputStream, "utf-8");
int evtType = xmlParser.getEventType();
while (evtType != XmlPullParser.END_DOCUMENT) {
switch (evtType) {
case XmlPullParser.START_TAG:
String tag = xmlParser.getName();
System.out.println(tag);
if (tag.equalsIgnoreCase("t")) {
river += xmlParser.nextText() + "\n";
}
break;
case XmlPullParser.END_TAG:
break;
default:
break;
}
evtType = xmlParser.next();
}
} catch (ZipException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (XmlPullParserException e) {
e.printStackTrace();
}
if (river == null) {
river = "解析文件出現問題";
}
return river;
}
public static String readXLSX(String path) {
String str = "";
String v = null;
boolean flat = false;
List ls = new ArrayList();
try {
ZipFile xlsxFile = new ZipFile(new File(path));
ZipEntry sharedStringXML = xlsxFile
.getEntry("xl/sharedStrings.xml");
InputStream inputStream = xlsxFile.getInputStream(sharedStringXML);
XmlPullParser xmlParser = Xml.newPullParser();
xmlParser.setInput(inputStream, "utf-8");
int evtType = xmlParser.getEventType();
while (evtType != XmlPullParser.END_DOCUMENT) {
switch (evtType) {
case XmlPullParser.START_TAG:
String tag = xmlParser.getName();
if (tag.equalsIgnoreCase("t")) {
ls.add(xmlParser.nextText());
}
break;
case XmlPullParser.END_TAG:
break;
default:
break;
}
evtType = xmlParser.next();
}
ZipEntry sheetXML = xlsxFile.getEntry("xl/worksheets/sheet1.xml");
InputStream inputStreamsheet = xlsxFile.getInputStream(sheetXML);
XmlPullParser xmlParsersheet = Xml.newPullParser();
xmlParsersheet.setInput(inputStreamsheet, "utf-8");
int evtTypesheet = xmlParsersheet.getEventType();
while (evtTypesheet != XmlPullParser.END_DOCUMENT) {
switch (evtTypesheet) {
case XmlPullParser.START_TAG:
String tag = xmlParsersheet.getName();
if (tag.equalsIgnoreCase("row")) {
} else if (tag.equalsIgnoreCase("c")) {
String t = xmlParsersheet.getAttributeValue(null, "t");
if (t != null) {
flat = true;
System.out.println(flat + "有");
} else {
System.out.println(flat + "沒有");
flat = false;
}
} else if (tag.equalsIgnoreCase("v")) {
v = xmlParsersheet.nextText();
if (v != null) {
if (flat) {
str += ls.get(Integer.parseInt(v)) + " ";
} else {
str += v + " ";
}
}
}
break;
case XmlPullParser.END_TAG:
if (xmlParsersheet.getName().equalsIgnoreCase("row")
&& v != null) {
str += "\n";
}
break;
}
evtTypesheet = xmlParsersheet.next();
}
System.out.println(str);
} catch (ZipException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (XmlPullParserException e) {
e.printStackTrace();
}
if (str == null) {
str = "解析文件出現問題";
}
return str;
}
public static String readPPTX(String path) {
List ls = new ArrayList();
String river = "";
ZipFile xlsxFile = null;
try {
xlsxFile = new ZipFile(new File(path));// pptx按照讀取zip格式讀取
} catch (ZipException e1) {
e1.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
}
try {
ZipEntry sharedStringXML = xlsxFile.getEntry("[Content_Types].xml");// 找到裡面存放內容的文件
InputStream inputStream = xlsxFile.getInputStream(sharedStringXML);// 將得到文件流
XmlPullParser xmlParser = Xml.newPullParser();// 實例化pull
xmlParser.setInput(inputStream, "utf-8");// 將流放進pull中
int evtType = xmlParser.getEventType();// 得到標簽類型的狀態
while (evtType != XmlPullParser.END_DOCUMENT) {// 循環讀取流
switch (evtType) {
case XmlPullParser.START_TAG: // 判斷標簽開始讀取
String tag = xmlParser.getName();// 得到標簽
if (tag.equalsIgnoreCase("Override")) {
String s = xmlParser
.getAttributeValue(null, "PartName");
if (s.lastIndexOf("/ppt/slides/slide") == 0) {
ls.add(s);
}
}
break;
case XmlPullParser.END_TAG:// 標簽讀取結束
break;
default:
break;
}
evtType = xmlParser.next();// 讀取下一個標簽
}
} catch (ZipException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (XmlPullParserException e) {
e.printStackTrace();
}
for (int i = 1; i < (ls.size() + 1); i++) {// 假設有6張幻燈片
river += "第" + i + "張················" + "\n";
try {
ZipEntry sharedStringXML = xlsxFile.getEntry("ppt/slides/slide"
+ i + ".xml");// 找到裡面存放內容的文件
InputStream inputStream = xlsxFile
.getInputStream(sharedStringXML);// 將得到文件流
XmlPullParser xmlParser = Xml.newPullParser();// 實例化pull
xmlParser.setInput(inputStream, "utf-8");// 將流放進pull中
int evtType = xmlParser.getEventType();// 得到標簽類型的狀態
while (evtType != XmlPullParser.END_DOCUMENT) {// 循環讀取流
switch (evtType) {
case XmlPullParser.START_TAG: // 判斷標簽開始讀取
String tag = xmlParser.getName();// 得到標簽
if (tag.equalsIgnoreCase("t")) {
river += xmlParser.nextText() + "\n";
}
break;
case XmlPullParser.END_TAG:// 標簽讀取結束
break;
default:
break;
}
evtType = xmlParser.next();// 讀取下一個標簽
}
} catch (ZipException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (XmlPullParserException e) {
e.printStackTrace();
}
}
if (river == null) {
river = "解析文件出現問題";
}
return river;
}
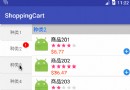 Android仿外賣購物車功能
Android仿外賣購物車功能
先看看效果圖:知識點分析效果圖來看不復雜內容並沒多少,值得介紹一下的知識點也就下面幾個吧 - 列表標題懸停 - 左右列表滑動時聯動 - 添加商品時的拋物線動畫 - 底部彈
 Android打造屬於自己的數據庫操作類。
Android打造屬於自己的數據庫操作類。
1、概述開發Android的同學都知道sdk已經為我們提供了一個SQLiteOpenHelper類來創建和管理SQLite數據庫,通過寫一個子類去繼承它,就可以方便的創建
 Unity3D —— protobuf網絡框架
Unity3D —— protobuf網絡框架
前言:protobuf是google的一個開源項目,主要的用途是:1.數據存儲(序列化和反序列化),這個功能類似xml和json等;2.制作網絡通信協議;一、資源下載:1
 Android開發之 SwipeRefreshLayout
Android開發之 SwipeRefreshLayout
SwipeRefreshLayout概述 用戶通過手勢或者點擊某個按鈕實現內容視圖的刷新,布局裡加入SwipeRefreshLayout嵌套一個子視圖如ListView、